Supervisé vs. Non Supervisé : La Grande Différence
Apprentissage Supervisé
Dans la régression et la classification, nous avions toujours une variable cible (la "réponse") :
- Régression: Prédire les ventes, le poids, le prix...
- Classification : Prédire si une tumeur est maligne/bénigne, si un email est spam/non-spam...
Analogie : C'est comme un professeur qui vous donne des exercices avec les réponses. Vous apprenez en voyant les bonnes réponses.
Apprentissage Non Supervisé (le Clustering)
Dans le clustering, il n'y a pas de variable cible. L'ordinateur doit trouver les groupes tout seul !
Analogie : C'est comme ranger des jouets dans des boîtes sans instructions. Vous devez décider vous-même quels jouets vont ensemble (les voitures ensemble, les poupées ensemble, les peluches ensemble...).
Le Critère Fondamental : La Distance
Question clé : Sans variable cible, comment l'ordinateur sait-il que deux éléments sont similaires ?
Réponse : Il utilise uniquement la distance entre les échantillons !
- Deux points proches (petite distance) → similaires → même groupe ✅
- Deux points éloignés (grande distance) → différents → groupes différents ❌
Analogie : Dans une soirée, les gens qui se connaissent se regroupent naturellement. Ils sont "proches" socialement. Le clustering fait la même chose avec des données, mais en mesurant la proximité avec une formule mathématique.
La distance utilisée est généralement la distance euclidienne (la distance "à vol d'oiseau", la plus courte).
Formule : Pour deux points (x₁, y₁) et (x₂, y₂) :
distance = √[(x₂ - x₁)² + (y₂ - y₁)²]
L'Algorithme K-means : Comment ça Marche ?
Les Objectifs du K-means
L'algorithme k-means cherche à créer K groupes (clusters) avec deux objectifs :
- Minimiser la distance à l'intérieur d'un groupe → groupes denses
- Maximiser la distance entre les groupes → groupes bien séparés
Analogie : C'est comme organiser des tables dans une salle de classe :
- Les élèves d'une même table doivent être proches les uns des autres (groupe dense)
- Les tables doivent être éloignées les unes des autres (groupes séparés)
Le Processus Itératif : Les 2 Étapes qui se Répètent
Le k-means est un processus itératif : il répète les mêmes actions plusieurs fois jusqu'à trouver la meilleure solution.
Étape 1 : Attribution des Données (Assignation)
Ce qui se passe :
- Chaque échantillon (chaque point) regarde tous les centroïdes (centres de groupe)
- Il calcule la distance qui le sépare de chaque centroïde
- Il est assigné au centroïde le plus proche
Analogie : C'est comme si chaque élève dans une classe s'asseyait à la table dont le centre est le plus proche de lui. Si un élève est à 2 mètres de la table A et 5 mètres de la table B, il va vers la table A.
En code :
# Pour chaque point, trouver le centroïde le plus proche
for point in data:
distances = [distance(point, centroid) for centroid in centroids]
point.cluster = argmin(distances) # Assigner au plus proche
Étape 2 : Mise à Jour des Centroïdes (Déplacement)
Ce qui se passe :
- Une fois que tous les points sont assignés, le centre de gravité (la moyenne) de chaque groupe est recalculé
- Le centroïde se déplace à cette nouvelle position
Analogie : Imaginez que les centres de table peuvent se déplacer. Après que tous les élèves se soient assis, chaque centre de table se repositionne pour être exactement au milieu de tous les élèves qui y sont assis.
En code :
# Recalculer la position de chaque centroïde
for cluster in clusters:
points_in_cluster = get_points_in_cluster(cluster)
new_centroid = mean(points_in_cluster) # Moyenne de tous les points
cluster.centroid = new_centroid
La Convergence : Quand S'Arrêter ?
Ces deux étapes se répètent jusqu'à ce que les centroïdes ne bougent presque plus.
Pourquoi s'arrêter quand les centroïdes ne bougent plus ?
Parce que cela signifie que le modèle a trouvé une configuration stable :
- Chaque point est déjà assigné au centroïde le plus proche
- Si on recalcule les centroïdes, ils tombent au même endroit
- Les groupes sont cohérents et optimaux
On dit que l'algorithme a convergé.
Analogie : C'est comme arrêter de réorganiser les meubles dans une pièce quand vous avez trouvé le meilleur agencement. Si vous bougez une chaise, vous la remettez au même endroit → c'est stable.
Illustration du Processus K-means
Voici comment l'algorithme k-means évolue étape par étape :
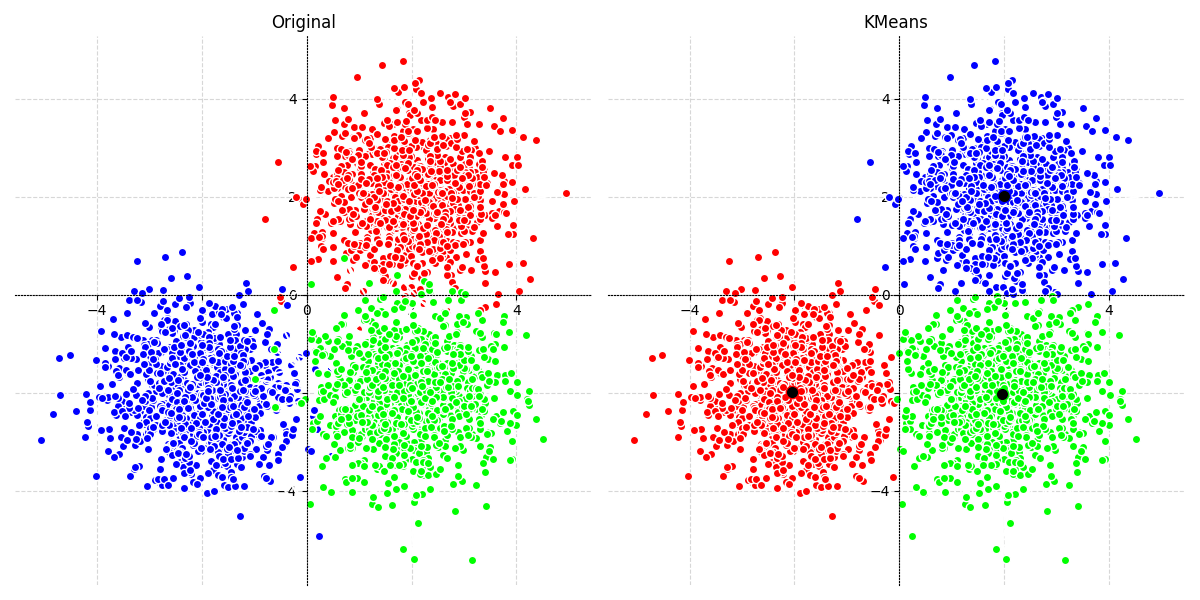
Ce que montre ce graphique :
- Gauche : Initialisation avec centroïdes aléatoires
- Milieu : Après quelques itérations, les groupes commencent à se former
- Droite : Convergence finale - les groupes sont bien définis et stables
Les couleurs représentent les différents clusters, et les étoiles (★) sont les centroïdes.
Évaluation du Clustering : Choisir le Bon K
Le Problème du Choix de K
Le point faible du k-means : il faut choisir le nombre de clusters K à l'avance !
- Si K = 2, on aura 2 groupes
- Si K = 5, on aura 5 groupes
- Mais quel est le bon K ?
Analogie : C'est comme essayer de ranger des livres. Combien de piles devez-vous faire ? 3 piles (romans, BD, documentaires) ? 5 piles (en ajoutant policiers et science-fiction) ? Il faut trouver le nombre qui a le plus de sens.
Le Coefficient de Silhouette
Le Coefficient de Silhouette est un score qui évalue la qualité des groupes en tenant compte de deux critères :
- Densité du groupe : Les points sont-ils proches dans leur groupe ?
- Séparation du groupe : Les groupes sont-ils éloignés des autres ?
Échelle du Coefficient de Silhouette :
| Score | Interprétation |
|---|---|
| +1 | Clustering parfait ✅ (groupes très denses et très bien séparés) |
| 0 | Clustering ambigu ⚠️ (les groupes se chevauchent) |
| -1 | Très mauvais clustering ❌ (points assignés au mauvais groupe) |
Formule simplifiée :
Silhouette = (distance au groupe le plus proche - distance moyenne dans son groupe)
/ max(les deux distances)
Comment Trouver le K Optimal ?
Méthode :
Essais Multiples : Entraîner le modèle avec différentes valeurs de K
- Essayer K=2, K=3, K=4... jusqu'à K=10
Calcul du Score : Pour chaque K, calculer le Coefficient de Silhouette
Observation Graphique : Tracer l'évolution du score
Choisir le Maximum : Le K qui donne le score le plus élevé (le pic) est le meilleur
Exemple de graphique :
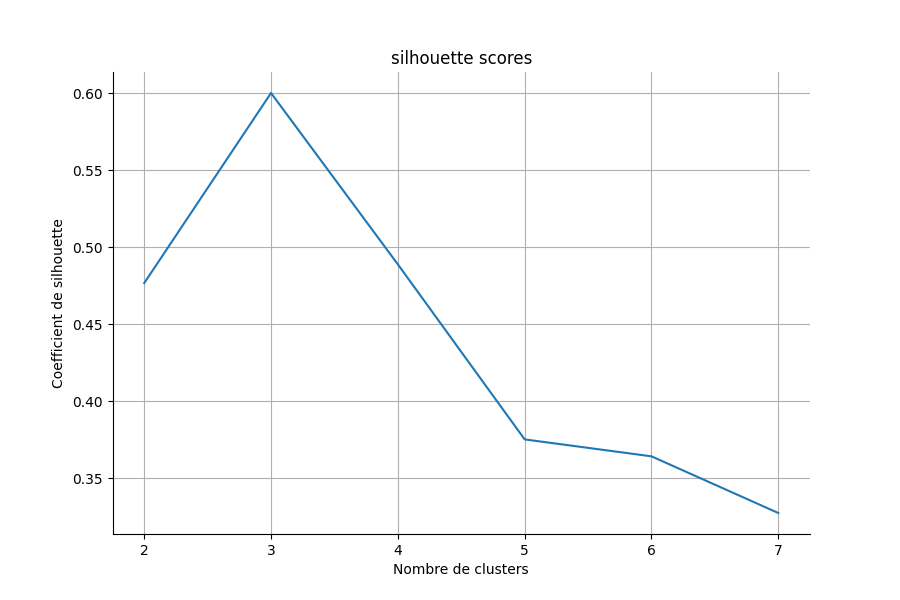
Lecture du graphique :
- L'axe horizontal montre le nombre de clusters (K)
- L'axe vertical montre le score de Silhouette
- Le pic indique le meilleur K
Dans cet exemple, K=3 est optimal car il donne le meilleur score (≈0.60).
Interprétation :
- K=3 donne le meilleur compromis entre groupes denses et bien séparés
- K=2 : pas assez de groupes, on mélange des choses différentes
- K=7 : trop de groupes, on divise des choses similaires
Application : Le Dataset Iris
Présentation du Dataset
Le dataset Iris est un classique du machine learning :
- 150 échantillons de fleurs
- 3 familles : Setosa, Versicolor, Virginica
- 4 caractéristiques : longueur/largeur des pétales et sépales
Analogie : C'est comme avoir 150 fleurs de 3 espèces différentes et mesurer la taille de leurs pétales et feuilles. Le défi : peut-on regrouper les fleurs similaires sans connaître leur espèce ?
Application du K-means
Paramètres :
- K = 3 clusters (on demande 3 groupes)
- Résultat : Coefficient de Silhouette = 0.55
Qu'est-ce que 0.55 signifie ?
Rappelons l'échelle :
- 1 = parfait
- 0 = ambigu
- -1 = mauvais
0.55 est à mi-chemin entre 0 et 1, ce qui indique :
- ✅ Le clustering a plutôt bien réussi
- ✅ Les groupes sont cohérents et bien séparés
- ⚠️ Ce n'est pas parfait, il y a un peu de chevauchement
Analogie : C'est comme obtenir 11/20 à un examen. Ce n'est pas excellent, mais c'est correct et au-dessus de la moyenne.
Comparaison avec les Vraies Familles
Question intéressante : Les 3 groupes trouvés par le k-means correspondent-ils aux 3 vraies familles de fleurs ?
Pour le savoir, on compare :
- Clusters trouvés par k-means (Cluster 0, 1, 2)
- Vraies familles du dataset (Setosa, Versicolor, Virginica)
Résultat : Accuracy = 88.7%
Qu'est-ce que 88.7% signifie ?
Cela signifie que le k-means a réussi à regrouper 88.7% des fleurs dans des clusters qui correspondent exactement à leurs vraies familles, sans jamais avoir vu les noms des familles pendant l'entraînement !
C'est impressionnant car :
- L'algorithme n'avait que les mesures physiques (longueur/largeur)
- Il n'avait aucune information sur les espèces
- Pourtant, il a retrouvé les groupes naturels avec 88.7% de précision
Analogie : C'est comme si on vous demandait de trier 150 photos de chiens en 3 piles (Berger Allemand, Golden Retriever, Chihuahua) sans vous dire les races. Vous devez juste observer les ressemblances. Si vous réussissez à 88.7%, c'est excellent !
Analyse de la Matrice de Confusion 🔍
Puisque 88.7% est une bonne performance, regardons les 11.3% d'erreurs (17 fleurs mal classées).
La Matrice de Confusion

| Prédit Cluster 0 | Prédit Cluster 1 | Prédit Cluster 2 | |
|---|---|---|---|
| Vraie Famille 0 | 50 ✅ | 0 | 0 |
| Vraie Famille 1 | 0 | 47 ✅ | 3 ❌ |
| Vraie Famille 2 | 0 | 14 ❌ | 36 ✅ |
Lecture de la matrice :
- Diagonale (50, 47, 36) : fleurs correctement regroupées ✅
- Hors diagonale (3, 14) : erreurs de regroupement ❌
Analyse Détaillée
Famille 0 (Setosa) : Perfection !
Vraie Famille 0 : 50 → Cluster 0
0 → Cluster 1
0 → Cluster 2
Interprétation :
- Toutes les 50 fleurs Setosa ont été correctement groupées
- 0 erreur : aucune confusion avec les autres familles
- Score : 100% pour cette famille
Qu'est-ce que cela signifie ?
Les fleurs Setosa ont des caractéristiques très distinctes des deux autres familles. Elles forment un nuage de points bien séparé.
Analogie : C'est comme avoir des Chihuahuas (très petits) parmi des Golden Retrievers et Bergers Allemands (grands). Le Chihuahua est tellement différent qu'il est facile à identifier.
Famille 1 (Versicolor) : Bon Résultat ✅
Vraie Famille 1 : 0 → Cluster 0
47 → Cluster 1 ✅
3 → Cluster 2 ❌
Interprétation :
- 47 fleurs sur 50 correctement groupées (94%)
- 3 fleurs confondues avec la Famille 2
Famille 2 (Virginica) : Le Plus d'Erreurs ⚠️
Vraie Famille 2 : 0 → Cluster 0
14 → Cluster 1 ❌ ← Plus grande erreur !
36 → Cluster 2 ✅
Interprétation :
- 36 fleurs sur 50 correctement groupées (72%)
- 14 fleurs confondues avec la Famille 1
Les Conclusions de l'Analyse
Observation 1 : Famille 0 Facile à Séparer
- Setosa est très distincte → 100% de réussite
- Ses caractéristiques (longueur/largeur) sont très différentes
Observation 2 : Familles 1 et 2 Se Chevauchent
- Versicolor et Virginica ont des caractéristiques similaires
- 14 + 3 = 17 erreurs entre ces deux familles
- C'est la preuve que leurs pétales/sépales ont des tailles proches
Analogie :
- Setosa = Chihuahua (facile à distinguer)
- Versicolor et Virginica = Golden Retriever vs Labrador Retriever (plus difficile car ils se ressemblent beaucoup)
Visualisation des clusters Iris :
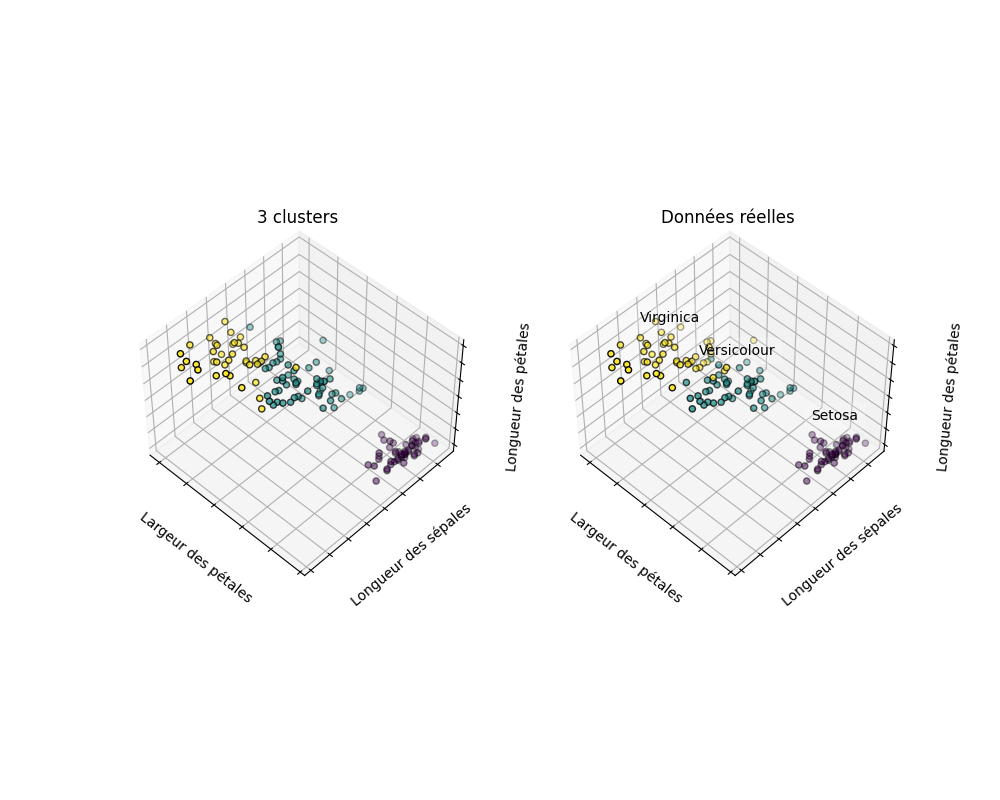
Ce que montre ce graphique :
- Chaque couleur représente un cluster trouvé par k-means
- On voit clairement que le cluster violet (Setosa) est bien séparé
- Les clusters orange et vert (Versicolor et Virginica) se chevauchent partiellement
Récapitulatif : Les Points Clés
Ce qu'est le Clustering
| Apprentissage Supervisé | Apprentissage Non Supervisé (Clustering) |
|---|---|
| On a une variable cible | ❌ Pas de variable cible |
| On apprend avec les réponses | On trouve les groupes soi-même |
| Régression, Classification | K-means, Clustering Hiérarchique |
Comment Fonctionne le K-means
- Initialisation : Choisir K centroïdes au hasard
- Itération :
- Étape 1 : Assigner chaque point au centroïde le plus proche (distance)
- Étape 2 : Recalculer les centroïdes (moyenne des points assignés)
- Convergence : Répéter jusqu'à ce que les centroïdes ne bougent plus
Comment Choisir K
- Essayer plusieurs valeurs de K (2, 3, 4...)
- Calculer le Coefficient de Silhouette pour chaque K
- Choisir le K qui donne le score maximum (pic de la courbe)
Comment Évaluer la Qualité
| Métrique | Interprétation |
|---|---|
| Coefficient de Silhouette | -1 (mauvais) à +1 (excellent) |
| Accuracy | Comparaison avec vraies classes (si disponibles) |
| Matrice de Confusion | Voir où sont les erreurs |
Cas d'Usage du Clustering
Segmentation de Clients
- Regrouper les clients par comportement d'achat
- Créer des campagnes marketing ciblées
Compression d'Images
- Réduire le nombre de couleurs en groupant les pixels similaires
- K-means pour la quantification des couleurs
Détection d'Anomalies
- Trouver des points isolés (pas dans aucun cluster dense)
- Détecter des fraudes, des pannes machines
Organisation de Documents
- Regrouper des articles par thème
- Créer des catégories automatiquement
Biologie
- Classifier des espèces selon leurs caractéristiques
- Exemple : Iris avec ses 3 familles
Limites du K-means
1. Il faut choisir K à l'avance
- Pas toujours évident de savoir combien de groupes existent
- Solution : Tester plusieurs K et utiliser le Coefficient de Silhouette
2. Sensible à l'initialisation
- Les centroïdes de départ sont aléatoires
- Peut donner des résultats légèrement différents
- Solution : Relancer plusieurs fois et garder le meilleur
3. Suppose des groupes sphériques
- K-means fonctionne mieux avec des groupes ronds
- Peut mal fonctionner avec des formes allongées ou complexes
4. Sensible aux valeurs extrêmes
- Un point très éloigné peut déplacer un centroïde
- Solution : Normaliser les données avant le clustering
Pour Aller Plus Loin
Autres Algorithmes de Clustering
- DBSCAN : Ne nécessite pas de choisir K, trouve des formes complexes
- Clustering Hiérarchique : Crée un arbre de groupes (dendrogramme)
- GMM (Gaussian Mixture Models) : Version probabiliste du k-means
Optimisations du K-means
- K-means++ : Meilleure initialisation des centroïdes
- Mini-batch K-means : Plus rapide pour de gros datasets
Visualisation
- PCA (Analyse en Composantes Principales) : Réduire à 2D pour visualiser
- t-SNE : Visualisation avancée de clusters en haute dimension
Conclusion
Le clustering est une technique puissante pour découvrir des structures cachées dans les données. Le k-means est l'algorithme le plus populaire car il est :
✅ Simple à comprendre
✅ Rapide à exécuter
✅ Efficace pour de nombreux cas d'usage
Son seul inconvénient : il faut choisir K. Mais avec le Coefficient de Silhouette, on peut trouver le K optimal !
L'exemple d'Iris montre que le k-means peut retrouver des groupes naturels (les 3 espèces de fleurs) avec 88.7% de précision, juste en analysant les mesures physiques. C'est la magie de l'apprentissage non supervisé ! 🌸✨