Régression vs Classification
Différence fondamentale
| Type | Objectif | Sortie | Exemple |
|---|---|---|---|
| Régression | Prédire un nombre | Valeur continue (n'importe quel chiffre) | Prix : 250 000€ |
| Classification | Classer dans une catégorie | Catégorie discrète (étiquette) | Spam : OUI ou NON |
Analogie :
- Régression = Donner une note sur 100 à un devoir
- Classification = Dire si l'élève a réussi (A/B/C/D/F)
Les Types de Classification
Classification Binaire ⚪⚫
Définition : Seulement 2 catégories possibles.
Exemples :
- Transaction : Fraude / Normale
- Email : Spam / Légitime
- Tumeur : Maligne / Bénigne
- Diagnostic : Malade / Sain
Représentation : 0 ou 1, Vrai ou Faux, Oui ou Non
Classification Multiclasse 🔴🔵🟢
Définition : Plus de 2 catégories différentes.
Exemples :
- Classifier des photos : Chien / Chat / Oiseau
- Note d'un film : ⭐ / ⭐⭐ / ⭐⭐⭐ / ⭐⭐⭐⭐ / ⭐⭐⭐⭐⭐
- Type de fleur : Iris / Rose / Tulipe
Classification Multilabel 🏷️🏷️
Définition : Un objet peut appartenir à plusieurs catégories simultanément.
Exemples :
- Film : "Action" ET "Comédie" ET "Science-Fiction"
- Article de presse : "Politique" ET "Économie"
- Maladie : Un patient peut avoir plusieurs pathologies
Catégories Ordinales vs Nominales
Ordinales : Il existe un ordre entre les catégories
- Mauvais < Moyen < Bon < Excellent
- Petite < Moyenne < Grande taille
Nominales : Pas d'ordre naturel
- Couleurs : Rouge, Bleu, Vert
- Pays : France, Japon, Brésil
La Régression Logistique : Le Pont entre Régression et Classification
Pourquoi "Régression" pour faire de la "Classification" ? 🤔
Le nom est trompeur ! La régression logistique utilise une régression pour faire de la classification.
Le Processus en 3 Étapes
Étape 1 : Régression Linéaire Classique
On commence comme avec la régression linéaire :
y = a × x₁ + b × x₂ + c × x₃ + d
Problème : y peut être n'importe quel nombre (-∞ à +∞)
- Si y = 150 → Que faire ?
- Si y = -50 → Ça n'a pas de sens pour une catégorie !
Étape 2 : Fonction Logistique (Sigmoïde)
On applique la fonction sigmoïde pour transformer y en probabilité z :
z = 1 / (1 + e^(-y))
Résultat : z est toujours entre 0 et 1 → c'est une probabilité !
Graphique de la fonction sigmoïde :
1 | ________
| /
z | /
| /
0 |_____/____________
-∞ 0 +∞
y
Propriétés magiques :
- Si y = -∞ → z ≈ 0 (impossible)
- Si y = 0 → z = 0.5 (50% de chances)
- Si y = +∞ → z ≈ 1 (certain)
Étape 3 : Seuil de Classification
On transforme la probabilité en décision ferme :
if z >= 0.5:
prédiction = 1 # Classe Positive
else:
prédiction = 0 # Classe Négative
Exemple concret :
- Probabilité de spam = 0.78 (78%) → SPAM ✅
- Probabilité de spam = 0.23 (23%) → LÉGITIME ✅
Évaluer la Performance : L'Exactitude
L'Exactitude (Accuracy)
C'est quoi ? Le pourcentage de prédictions correctes.
Formule :
Exactitude = Nombre de bonnes prédictions / Nombre total de prédictions
Exemple :
- 100 emails testés
- 95 bien classés (spam ou légitime)
- Exactitude = 95% 🎉
Le Paradoxe de l'Exactitude 😱
Problème : L'exactitude peut être trompeuse !
Exemple de la Fraude Bancaire :
- Dans 100 transactions, seulement 1 est frauduleuse (1%)
- Un modèle stupide qui dit TOUJOURS "Pas de fraude" aura :
- 99 bonnes prédictions (les 99 légitimes)
- 1 erreur (la fraude non détectée)
- Exactitude = 99% 😮
Conclusion : Ce modèle est inutile car il ne détecte aucune fraude, mais il a un score "excellent" !
C'est pourquoi on a besoin d'outils plus fins...
La Matrice de Confusion : Le Détective des Erreurs
Qu'est-ce que c'est ?
Un tableau 2×2 qui croise Réalité vs Prédiction pour voir les 4 résultats possibles.
Les 4 Résultats Possibles
| Prédiction : Positif | Prédiction : Négatif | |
|---|---|---|
| Réalité : Positif | ✅ Vrai Positif (TP) | ❌ Faux Négatif (FN) |
| Réalité : Négatif | ❌ Faux Positif (FP) | ✅ Vrai Négatif (TN) |
Explications avec Exemples
✅ Vrai Positif (TP - True Positive)
- Réalité : Malade
- Prédiction : Malade
- Résultat : Bien détecté ! 👍
✅ Vrai Négatif (TN - True Negative)
- Réalité : Sain
- Prédiction : Sain
- Résultat : Bien ignoré ! 👍
❌ Faux Positif (FP - False Positive)
- Réalité : Sain
- Prédiction : Malade
- Résultat : Fausse alerte ! 🚨 (Alarme inutile)
Exemple : Email légitime envoyé dans les spams
❌ Faux Négatif (FN - False Negative)
- Réalité : Malade
- Prédiction : Sain
- Résultat : Cas manqué ! 😰 (Danger non détecté)
Exemple : Maladie non diagnostiquée
Quelle est l'Erreur la Plus Grave ? 🚨
Dans le contexte médical : Le Faux Négatif (FN) est catastrophique !
- Le patient est malade mais le modèle dit qu'il est sain
- La maladie n'est pas traitée → Conséquences potentiellement fatales
Dans le contexte du spam : Le Faux Positif (FP) est plus gênant
- Un email important est classé comme spam
- Risque de manquer une information cruciale
Le Rappel (Recall) : Ne Rien Manquer
Définition
Le Rappel mesure la capacité du modèle à détecter tous les cas positifs.
Question clé : Parmi tous les malades réels, combien ai-je détectés ?
Formule
Rappel = TP / (TP + FN)
Décryptage du dénominateur :
TP= Vrais Positifs (bien détectés)FN= Faux Négatifs (malades manqués)TP + FN= TOUS les cas réellement positifs dans les données
Exemple Concret
Contexte : Détection de cancer, 100 patients, 20 sont malades
| Résultat | Nombre |
|---|---|
| Vrais Positifs (TP) | 18 (détectés) |
| Faux Négatifs (FN) | 2 (manqués) |
| Total de malades réels | 20 |
Calcul :
Rappel = 18 / (18 + 2) = 18 / 20 = 0.90 = 90%
Interprétation : Le modèle détecte 90% des malades, mais en manque 10% (2 personnes).
Quand privilégier le Rappel ?
✅ Situations critiques où manquer un cas est dangereux :
- Détection de maladies graves
- Détection de fraudes financières
- Détection d'intrusions informatiques
- Contrôle qualité (défauts de fabrication)
Objectif : NE RIEN MANQUER, même si ça génère des fausses alertes.
La Précision (Precision) : Éviter les Fausses Alertes
Définition
La Précision mesure la fiabilité des alertes du modèle.
Question clé : Parmi toutes mes alertes positives, combien étaient vraies ?
Formule
Précision = TP / (TP + FP)
Décryptage du dénominateur :
TP= Vrais Positifs (alertes correctes)FP= Faux Positifs (fausses alertes)TP + FP= TOUTES les fois où le modèle a dit "Positif"
Exemple Concret
Contexte : Filtre anti-spam, 1000 emails
| Résultat | Nombre |
|---|---|
| Vrais Positifs (TP) | 180 (vrais spams détectés) |
| Faux Positifs (FP) | 20 (emails légitimes classés spam) |
| Total d'alertes spam | 200 |
Calcul :
Précision = 180 / (180 + 20) = 180 / 200 = 0.90 = 90%
Interprétation : Quand le filtre dit "SPAM", il a raison 90% du temps, mais se trompe 10% du temps (20 emails légitimes perdus).
Quand privilégier la Précision ?
✅ Situations où les fausses alertes sont coûteuses :
- Filtre anti-spam (ne pas perdre d'emails importants)
- Système de recommandation (ne pas recommander n'importe quoi)
- Publicité ciblée (ne pas gaspiller le budget sur les mauvaises cibles)
Objectif : Être SÛR de ses alertes, même si on en rate quelques-unes.
Le Compromis Précision / Rappel
Le Dilemme
Problème : On ne peut pas maximiser les deux en même temps ! 😰
Scénario 1 : Modèle Ultra-Prudent (Précision Élevée)
Comportement : Le modèle ne dit "Positif" que quand il est TRÈS SÛR.
Conséquences :
- ✅ Précision élevée : Peu de fausses alertes (FP↓)
- ❌ Rappel faible : Beaucoup de cas manqués (FN↑)
Analogie : Un détecteur de fumée qui ne sonne que si la maison est en flammes
- Pas de fausses alarmes ✅
- Mais il rate les petits débuts d'incendie ❌
Scénario 2 : Modèle Ultra-Sensible (Rappel Élevé)
Comportement : Le modèle dit "Positif" au moindre doute.
Conséquences :
- ✅ Rappel élevé : Peu de cas manqués (FN↓)
- ❌ Précision faible : Beaucoup de fausses alertes (FP↑)
Analogie : Un détecteur de fumée ultra-sensible
- Il détecte tout ✅
- Mais il sonne pour un toast brûlé ❌
Le Rôle du Seuil de Classification
Rappel : On transforme la probabilité en décision avec un seuil (par défaut 0.5).
if probabilité >= seuil:
prédiction = Positif
else:
prédiction = Négatif
Baisser le Seuil (ex: 0.3)
if probabilité >= 0.3: # Plus facile de dire "Positif"
prédiction = Positif
Effet :
- 📈 Rappel augmente (on détecte plus de positifs)
- 📉 Précision diminue (plus de fausses alertes)
Augmenter le Seuil (ex: 0.7)
if probabilité >= 0.7: # Plus difficile de dire "Positif"
prédiction = Positif
Effet :
- 📉 Rappel diminue (on manque plus de positifs)
- 📈 Précision augmente (moins de fausses alertes)
Tableau Récapitulatif (Détection Cancer du Sein)
| Seuil | Précision | Rappel | Interprétation |
|---|---|---|---|
| 0.3 | 92.86% | 98.32% | Modèle sensible : détecte presque tout, quelques fausses alertes |
| 0.5 | 95.00% | 96.00% | Équilibré |
| 0.7 | 96.58% | 94.96% | Modèle prudent : alertes très fiables, rate quelques cas |
La Courbe ROC et l'AUC : Vue Globale
Problème
Comment évaluer un modèle indépendamment du seuil choisi ?
La Courbe ROC (Receiver Operating Characteristic)
Principe : Tracer le graphique du Rappel vs Taux de Faux Positifs pour tous les seuils possibles.
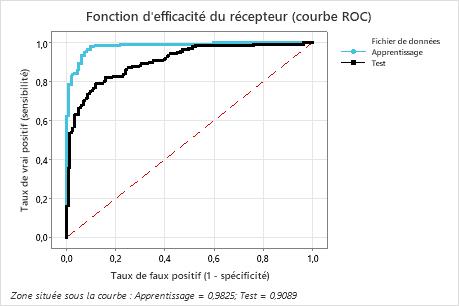
Axes :
- Axe Y : TPR (True Positive Rate) = Rappel = TP / (TP + FN)
- Axe X : FPR (False Positive Rate) = FP / (FP + TN)
1 | 📈
| /|
TPR | / | ← Courbe du modèle
| / |
0 |/_____|_____
0 0.5 1
FPR
Interprétation de la Courbe
Modèle Aléatoire (AUC = 0.5)
1 |
| /
TPR | / ← Diagonale = Tirage au sort
| /
0 |/_________
0 1
FPR
Signification : Le modèle est aussi bon qu'une pièce de monnaie 🪙
- Performance équivalente au hasard
- Inutile !
Modèle Parfait (AUC = 1.0)
1 |_____
| |
TPR | | ← Coin supérieur gauche
| |
0 |____|_____
0 1
FPR
Signification :
- TPR = 100% (tous les positifs détectés)
- FPR = 0% (aucune fausse alerte)
- Modèle idéal ! 🏆
Modèle Réaliste (AUC = 0.85)
1 | ___
| / |
TPR | / |
| / |
0 |/_____|___
0 1
FPR
Signification : Bon modèle, mais pas parfait
- Compromis entre détection et fausses alertes
L'AUC (Area Under the Curve)
Définition : La surface sous la courbe ROC.
Échelle d'interprétation :
| AUC | Qualité du Modèle | Interprétation |
|---|---|---|
| 0.5 | 💀 Aléatoire | Aussi bon qu'une pièce |
| 0.6-0.7 | 😐 Faible | Peu fiable |
| 0.7-0.8 | 👍 Acceptable | Utilisable |
| 0.8-0.9 | 🎯 Bon | Très performant |
| 0.9-1.0 | 🏆 Excellent | Modèle de production |
| 1.0 | 🦄 Parfait | Probablement surapprentissage ! |
Avantage : Métrique unique qui résume la performance sur tous les seuils.
Résumé : Quand Utiliser Quelle Métrique ?
Tableau de Décision
| Situation | Métrique à Privilégier | Raison |
|---|---|---|
| Détection de maladie grave | 🎯 Rappel | Manquer un malade est catastrophique |
| Filtre anti-spam | 🔍 Précision | Perdre un email important est problématique |
| Détection de fraude | 🎯 Rappel | Ne pas détecter une fraude coûte cher |
| Recommandation de produits | 🔍 Précision | Recommander n'importe quoi énerve l'utilisateur |
| Évaluation générale | 📊 AUC | Vision globale indépendante du seuil |
| Dataset équilibré | ✅ Exactitude | Quand les classes sont représentées équitablement |
🎓 Concepts Clés à Retenir
1. Régression Logistique
✅ Utilise une régression linéaire + fonction sigmoïde
✅ Donne une probabilité entre 0 et 1
✅ Transformée en décision via un seuil (par défaut 0.5)
2. Matrice de Confusion
✅ TP : Vrai Positif (bien détecté)
✅ TN : Vrai Négatif (bien ignoré)
❌ FP : Faux Positif (fausse alerte)
❌ FN : Faux Négatif (cas manqué)
3. Métriques
✅ Exactitude : % de bonnes prédictions (attention au paradoxe !)
✅ Rappel : TP / (TP + FN) → Détecter tous les positifs
✅ Précision : TP / (TP + FP) → Fiabilité des alertes
✅ AUC : Surface sous courbe ROC → Évaluation globale
4. Compromis Précision/Rappel
✅ On ne peut pas maximiser les deux en même temps
✅ Le seuil permet d'ajuster le compromis
✅ Choix dépend du contexte métier
💡 Analogies pour Bien Comprendre
Le Détecteur de Fumée
Rappel = Détecteur ultra-sensible
- ✅ Détecte TOUS les incendies (même petits)
- ❌ Sonne pour un toast brûlé (fausses alertes)
Précision = Détecteur prudent
- ✅ Ne sonne que pour les vrais incendies
- ❌ Rate les petits débuts de feu
Le Contrôle de Sécurité à l'Aéroport
Rappel = Fouiller tout le monde systématiquement
- ✅ Aucun danger ne passe
- ❌ Files d'attente interminables
Précision = Fouiller seulement les suspects évidents
- ✅ Flux rapide, peu de personnes embêtées
- ❌ Risque de laisser passer un danger